


A Vision of LLM-Native Media
Conversations: When Kernels and Agents Combine

It’s often the case that new creative technology is first met with old lenses of seeing the world. With generative AI (using LLMs), it’s mostly seen as a way to shortcut process to create new visions from humanity’s corpus of media. Crudely, you put in a prompt (or iterating over many prompts) and the machine generates an approximation.

Here, I gave ChatGPT the first chapter of my debut novel (“Hope Runners of Gridlock”) and asked it to draw a scene from it. It’s Flora, Esper, and Palma in the city of Gridlock watching the latest Hope Runner venture into the horizon (scale is a bit off, but decent approximation).
But, is this (mostly) one-way process of generating media from a prompt, actually anachronistic? If we dive deeper into the medium, what media is a better fit for it?
In a co-composting collab with , we set out to do research together and from that foundation wrote our own conclusions of what AI-Native media might come to look like.
It’s Not Just About Shortcuts
As a creator in many domains (art, music, writing), I’ve played with generative media, but I’m also deeply interested in the journey of process. So, sometimes, a shortcut, for me, defeats the purpose. It’s like hiking if the only goal was to get to the top of the mountain, and not enjoying the scenery along the way. I *like* being stuck in the plot, where my characters wrestle back with me through the pages, arguing that what I’ve written for them is too obvious and on the nose. I’m just as much having a conversation with them as they do among themselves. But, each creator chooses their own process, whether it’s years of fine art study or the conceptual sophistry of Dadaist Readymades. Process itself is always open to critique. Is process a necessity? Is *requiring* process to be deemed noteworthy or beautiful not limiting one’s ability to see beauty in new and unexpected domains?

It’s easy to judge generative LLM media with a lens of the past. As Cristobal (of RunwayML) notes:
When photography emerged, we made a critical error: we let painters judge it. Because on the surface it looked similar. They dissected this new form through the lens of their own medium, anchoring on what they knew. Predictably, they concluded photography would never match oil's texture, never capture color the way mixed pigments could. They were right and also completely missed the point. Photography wasn't trying to be painting. They were thinking by analogy, judging the new by the standards of the old.
It’s harder to judge it when you’re trying to spot nascent use of it that will evolve into a form of new media. Simply using it as a prompting engine isn’t wrong, but it can also be equated to a painter saying that they’ve painted a photo. Sure, when photography arrived, some painters loved that they could now focus far more on the composition, per se, versus the process of putting oil to canvas, but, there’s ultimately more to the medium of generative AI.
To me, LLM-native media that is unique to itself rests on the following points:
The model (or context) is the kernel of the media.
The media is explored through an accompanying agent.
Putting it differently, LLM-native media emphasises exploration and improvisation. This can happen organically, or on purpose. The ability for it to shortcut process is a key feature, much in the same that when the web arrived, we could send a “like” as communication when doing so with snail mail would’ve not made sense.
If one takes a McLuhan lens to it (the medium is the message), it looks like this:
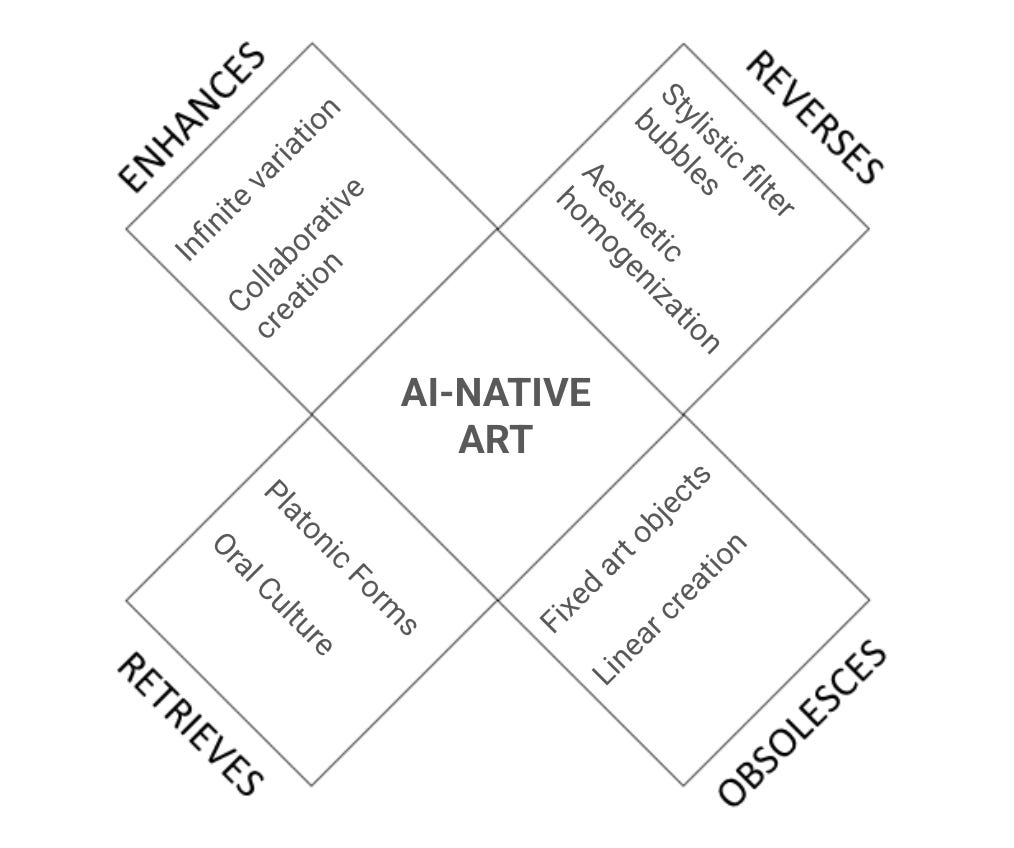
Let’s dive deeper.
Model (or context) as Kernel
My favourite example of this nascent exploration is Holly Herndon and Mat Dryhurst’s xhairymutantx that was commissioned for the 2024 Whitney Biennial. It is the basis of the belief of the “model” being the “art”:
Here on artport, the artists have trained a text-to-image AI model on images of Holly that have been altered through costuming that distorts the artist’s body, and exaggerates her most noted feature, her hair, to transform her identity within AI models. No matter what text prompt is entered by the user, the results will generate a strange version of Holly.
People could prompt the model, and no matter what they tried to make the model do, it would always include some version of Holly.

In this case, the model itself constrained itself. The kernel is Holly and the latent space is any variation of it.
In their case, the model was trained as such, but one can also inject a generic model with context (such as a system prompt or just a prompt variation).
Famous examples of this is the usage of LLM-media in fan-fiction. The kernel is generated from a base prompt. It’s locating the kernel in the latent space. Harry Potter has been such an example with fans generating everything: from fashion models (Balenciaga Harry) to imagining what raves/parties would be like for each house.
The point of constraining a kernel is to essentially elevate that part of the latent space as myth. Myth is archetypal. It’s the opposite of canon. It’s supposed to represent an idea and forms are interpretations of the idea. This is, in some sense, a return to more primitive approach to media, one before copyright or stronger notions of intellectual property. Storytellers passed down stories in oral traditions, and bards sang folk songs that have long lost knowledge of its source. It *was* media that existed in aggregate, in the collective, not by someone or something.
Ultimately, the kernel is supposed to not have some canonical form, even in cases where it’s used to reference existing media. It’s the “idea” of Harry Potter, not *the* Harry Potter.
And thus, the question remains: what makes good kernels? Before that, let’s dive into the second component.
The Accompanying Agent
When the kernel is supposed to be prodded into life, you need some way to interact with it, and that’s the agent. For the most part, the agent has been used quite objectively: it treats you as the interpreter as the only source. For example, when you prompt: “draw sword with flames on it”, your prompt isn’t modified in any sense. But, there’s exploration on treating the agent as a narrator and interpreter in its own right.
An example of how to see like an agent, is to check out author
’s usage of an LLM as a translator. In this example, he uses a Chinese poem and asks the LLM to reinterpret it with different lenses.In this way, the object of exploration became more alive by opening the fog of war around it. In some sense, you are tasking it to create different maps of the same territory and through that you are able to hold more models of the world.
But, what if the agent itself is opinionated? If we look back to primitive forms of storytelling, that’s exactly what it used to be: each person retelling a story added their own filter to it. An agent can act as that filter, interpreting media through *many* lenses. For example: What’s a modernist review of Severance? What’s an indie musician’s review of Severance? What’s a zoologist’s review of Severance?
In Her (2013), we see great examples of this. Theodore uses Samantha as an agent to see the world through her eyes. In a very specific scene, he plays a game, where not just Samantha but also an NPC from the game interacts not just with the game world, but with both of them. There are two agents involved.
A primitive from of this kind of agent is Amazon’s X-Ray in Prime. When you pause, it brings up bonus information you might want to know about the scene you’re watching.
With LLMs, you always have the ability to reinterpret through the assistance of an agent and that forms another core of LLM-native media.
Conversations: Kernels and Agents Combined
As a proto-example, xhairymutantx asked viewers to consider what the latent space itself was and that in itself was a conversation between viewer and model. The best combinations of kernels with agents (using LLMs at the source and LLMs at the interpretation layer) are thus new forms of conversations. It’s why the most popular form of interacting with LLMs have been chatbots themselves, and increasingly, people treating it as companions (from wireborn boyfriends to always-on patient therapists). But, again, conversations are still a proto-form in itself. It’s about seeing conversations-as-a-medium.
Let me explain with an example:
Imagine building a kernel, training a model with fictional tomes of a long abandoned civilization found on an alien planet. The more texts there are, the more you are priming the kernel. And now, you, as the agent can constantly probe this mythic civilization. There’s no canon to it, only interpretation. You can ask it to build fictional cities, ask it to invent leaders, ask it to invent physics, ask it to draw maps of the world, etc. But, every interpreter understands that all they are doing is interfacing with the ghost of this civilization. It’s only through constant conversation that us (“humans-as-interpreters”) can seek to understand what life was like on this fictional planet. Maybe, as a collaborative creative-writing exercise, people build a wiki of it. But, like SCP, there’s no canon, it’s only inscriptions, and conversations, competing narratives of this place that once existed. If you need aid, you can task an agent to help you, interpreting your prompts with scientific, philosophical, geological, anthropological, and linguistic perspectives.
The only way this media “becomes” something is through constant exploration and improvisation.
Or perhaps, a bit closer to reality, in the vein of Coffee Shop AU, you create a kernel of a fictional coffee shop, all with a rotating cast of strangers and regulars. There’s never a canonical coffeeshop, but rather the kernel focuses on the thematic elements of it: that of the joy of a local neighbourhood third place. But, not a real place, a mythical place that represents connection. As an interpreter, you frequent this coffee shop. As a collective, you go there together. With an agent, you might ask it to help you interact with the latent space of people in it.
While xhairymutantx and the above examples are more explicit, this process does also occur organically and memetically. A good example is the Italian brainrot animals.

As
writes:What’s happening here is the creation of an internet-native folklore, a collaborative mythmaking playing out over weeks and months rather than generations, generating an absurdist pantheon that roots itself in collective vibe rather than cultural memory.
Memes and meme-making itself is a proto-form of this type of media, because memes are in itself a conversation that’s continually expanding concepts, ideas, and encapsulations of feeling and intent.
Conclusion: Hello, Claude Shannon, My Dear Old Friend
Admittedly, with all these examples, it still feels like putting a round peg into a square hole. It feels that like SCP, being perfected by a wiki-as-medium, I don’t think we’ve entirely captured a kernel or agent that encompasses the full spectrum of this medium. It’s inching towards it, and Harry Potter x Balenciaga, Italian Brainrot Animals, xhairymutantx, etc are all proto-examples.
If I would guess, then there’s perhaps a type of media that fits this type of conversation well, is that it might not be focused on being particularly legible, but instead focuses on generating media that’s all about its tone, rather than its form. It’s not just about prompting familiar forms from generative AI. It’s not just asking it to replace film, novels, art, music, etc. Tone-based media is media that focuses on generating a feeling first before other forms of legibility (like plot, narrative, characters, etc). It’s vibes, slop, and timbre, all mashed together. It’s at the same time very detached, self-aware, cynical, but also choosing to be sincere about what it wants to be. In some sense, the the outputs themselves are merely venues for a conversation even if it’s all about Italian brainrot animals. We’re able to more rapidly produce intent and when we can do that, we can have more conversations.
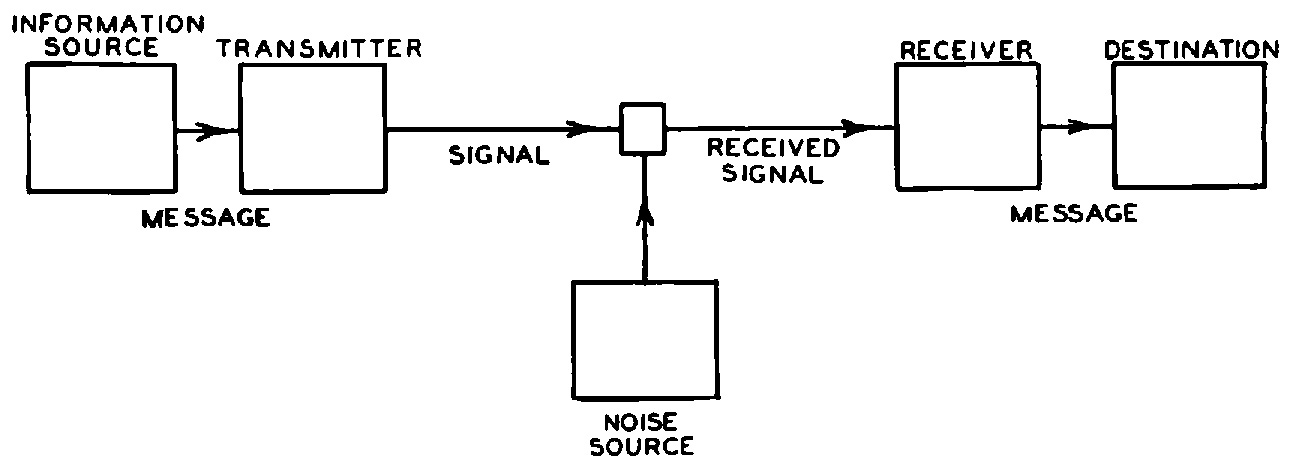
In Information Theoretic terms, LLMs-as-media boosts both the transmitters and the receivers. We’re able to generate far denser messages and also interpret them more rapidly. To paraphrase William Gibson: the conversations are already here, it’s not just evenly distributed.
ohhh thanks for the mention ˖⁺‧₊˚♡˚₊‧⁺˖♡︎˖⁺‧₊˚♡˚₊‧⁺˖
I love the concept behind xhairymutantx - I just joined a company called TITLES (titles.xyz) - and that's exactly what we're trying to do - help artists train their own AI models that anyone can use to create in their style, while retaining ownership and doing attribution thru blockchain. would love to tell you more about it if you're interested